11.3.4 General Stellar Parametrizer from Spectroscopy (GSP-Spec)
Author(s): Alejandra Recio-Blanco, Marco A. Álvarez
Goal
GSP-Spec (Recio-Blanco et al.2023) estimates the stellar atmospheric parameters, individual chemical abundances and Diffuse Interstellar Band (DIB) parameters from combined RVS spectra of single stars. No additional information (astrometric, photometric or BP/RP data) is considered, allowing a purely spectroscopic treatment. Two different algorithms described in Recio-Blanco et al. (2016), MatisseGauguin and ANN, are applied for atmospheric-parameter estimation. Individual abundances and DIB parameters are only estimated from the MatisseGauguin atmospheric parameters, using the Gauguin algorithm (Recio-Blanco et al.2006) and Gaussian fitting methods (Zhao et al.2021), respectively. Uncertainties are estimated from 50 Monte Carlo realisations considering the spectral flux uncertainties per pixel provided by CU6. For each realisation, a new complete parameterisation, from atmospheric parameters to related chemical abundances and DIB parameters, is performed. Upper and lower confidence values are provided from quantiles 84th and 16th, respectively.
Inputs
GSP-Spec uses as input combined RVS spectra and their flux uncertainties per pixel. The spectra are continuum normalised from CU6 pipelines, however, GSP-Spec reviews the continuum placement during the spectra parameterisation procedure. In addition, the spectra are rebinned from 2400 pixels to 800 pixels (without reducing the spectral resolution thanks to the RVS oversampling), allowing to increase their signal-to-noise (SNR) ratio. The RVS spectra analysed by GSPspec during DR3 operations were selected to have SNR20 before resampling.
Further input data are model grids of synthetic RVS spectra. The spectra have been derived from MARCS atmospheric models of FGKM-type stars (Gustafsson et al.2008), using the TURBOSPECTRUM spectral synthesis code (Plez 2012).
The associated line lists are those of Contursi et al. (2021). These models are used for the stellar atmospheric parameters (, , and [/Fe]), but also for the individual abundances estimate, for which a fifth dimension is added on [X/Fe], with X being the considered chemical element. We used an empirical law for the microturbulence parameter. This parametrized relation is a function of , and , and has been derived from literature values for the Gaia-ESO Survey (Bergemann et al., in preparation).
Methods
Two main procedures are implemented in GSP-Spec: MatisseGauguin (results published in the table astrophysical_parameters) and ANN (published in the astrophysical_parameters_supp table). Please refer to Recio-Blanco et al. (2023) for a detailed description of the methodology.
The MatisseGauguin parameterisation procedure, producing the GSP-Spec atmospheric parameters, individual chemical abundances and DIB parameters included in the astrophysical_parameters table, is as follows:
1.
Stellar parameters initialization with DEGAS: Once the RVS spectra are rebinned to 800 pixels, the DEGAS decision tree method (Kordopatis et al.2011), considering the entire parameter space of the grid (FGKM-type stars), is used to derive a first guess in , , and [/Fe].
2.
Matisse algorithm application: The MATISSE algorithm (Recio-Blanco et al.2006) is applied following an iterative procedure in the parameter estimation to overcome non-linearity problems. MATISSE is a projection method in the sense that the full input spectra are projected into a set of vectors derived during a learning phase, based on the noise-free reference grids. The noise optimization is taken into account thanks to a Landweber algorithm during the covariance matrix inversion and it is adapted to each application. These vectors are a linear combination of reference spectra and could be viewed roughly as the derivatives of these spectra with respect to the different stellar parameters. MATISSE is, thus, a local multi-linear regression method. The MATISSE projection is first applied around the DEGAS solution in a local environment of 500 K in , 0.5 dex in , 0.25 dex in and 0.20 dex in [/Fe]. This produces a second solution around which MATISSE is applied again. This iterative procedure is repeated until convergence, within a maximum of 10 iterations.
3.
Refinement of parameters with GAUGUIN: The GAUGUIN algorithm is applied around the final MATISSE solution of the previous step, considering a local environment of 250 K in , 0.5 dex in , 0.25 dex in and 0.20 dex in [/Fe]. GAUGUIN (Bijaoui et al.2012; Recio-Blanco et al.2016) is a classical, local optimization method implementing a Gauss-Newton algorithm. It is based on a local linearization around a given set of parameters that are associated with a reference synthetic spectrum (via linear interpolation of the derivatives).
Its goal is to find the direction in the parameter space that has the highest negative gradient as a function of the distance. Once this direction is found, the method proceeds in an iterative way, by modifying the initial guess of the studied parameter and re-calculating the gradient again, until convergence of the parameter solution.
A few iterations are carried out through linearization around the new solutions, until the algorithm converges towards the minimum distance. In practice, and to avoid trapping into secondary minima, GAUGUIN is initialized by parameters independently determined by other algorithms such as MATISSE. The final MATISSE+GAUGUIN solution in , , and [/Fe] is considered in the following.
4.
Continuum placement and spectra normalization: The parameters solution of the previous step is used to re-estimate the continuum placement. This step is particularly important in the case of cool stars, having pseudo-continuum flux values lower than one. The continuum placement and normalization procedure is described in detail in Santos-Peral et al. (2020). In this step, the spectrum flux is normalised over the entire RVS wavelength domain. To this purpose, the observed spectrum (O) is compared to an interpolated synthetic one (S) with the same atmospheric parameters. First, the most appropriate pixels of the residual (R = S/O) are selected using an iterative procedure implementing a linear fit to R followed by a clipping. Then, the residual trend is fitted with a low degree polynomial. Finally, the normalised spectrum is obtained after dividing the observed spectrum by a linear function resulting by the fit of the residual.
5.
Iteration in the atmospheric parameters solution following the continuum refinement: The module comes back to step 1, to re-estimate the atmospheric parameters using the new spectra normalization. This loop is performed five times, iterating on the parameters and the continuum placement. The final parameters solution in , , and [/Fe] is saved in the memory, as well as the final normalized spectrum. A goodness-of-fit (g.o.f.) between the observed and the synthetic spectrum interpolated to the final atmospheric parameters is derived and saved. This g.o.f. is reported in the final table only for the original observed spectra, not including Monte Carlo variations of the flux (see step 8).
6.
Chemical abundances per spectral line using GAUGUIN: Considering the final atmospheric parameters solution and normalized spectrum, selected spectral lines are considered for individual chemical abundance estimates. For each line identified in the list, a specific reference synthetic spectra grid is interpolated at the input atmospheric parameters in order to measure the abundance from the related chemical element responsible for the line absorption. This grid now includes a large range in the element abundance dimension (AX). First of all, a local normalization around the line is performed (Santos-Peral et al.2020). A minimum quadratic distance is then calculated between the reference grid and the observed spectrum, providing a first guess of the abundance estimate (A0). This first guess is optimised via the GAUGUIN algorithm, carrying out iterations through linearisation around the new solutions. The algorithm stops when the relative difference between two consecutive iterations is less than a given value (typically one hundredth of the grid abundance step).
7.
Diffuse Interstellar Band parameters: After a specific local normalisation around the DIB feature at 862 nm, the DIB parameters are extracted (Zhao et al.2021). More particularly, the DIB characteristics are derived from the spectra of late-type stars by subtracting the corresponding synthetic spectra. For early-type stars we applied a specific model based on the Gaussian process that needs no prior knowledge of the stellar parameters.
8.
CN over/under abundance proxy: a cyanogen line is analysed subtracting the corresponding synthetic spectra and estimated the equivalent width of the remaining feature (the value is positive for a CN over-abundance or negative for a CN under-abundance with respect to the standard value of [CN/Fe]=0.0 dex. To this purpose, the same Gaussian fitting procedure employed for DIB parameters of late-type stars is used, although allowing negative equivalent width values for CN under abundances.
9.
Monte Carlo iterations using flux uncertainties: flux uncertainties provided by CU6 are used to estimate the uncertainties in the GSP-Spec output parameters. To this purpose,
50 Monte Carlo realizations of the spectral flux are implemented. Variations of the spectral flux per pixel are generated, following a Gaussian distribution whose standard deviation is equal to the input flux uncertainties. For each realisation, a new complete parameterisation is performed, starting from step 1. This allows final set of 50 values for each atmospheric parameter, each spectral-line abundance and each DIB fitting parameter. Thanks to this, median, upper and lower confidence values are provided from quantiles 50th, 84th and 16th, respectively.
10.
Individual chemical abundances per element: The final chemical abundances per element are derived by combining the independent abundance estimates of all the lines of the same element. To this purpose, a weighted mean is calculated, using the inverse of the line-abundance uncertainty (defined as the upper minus lower abundance value of all the MC realisations of that line abundance) as a weight.
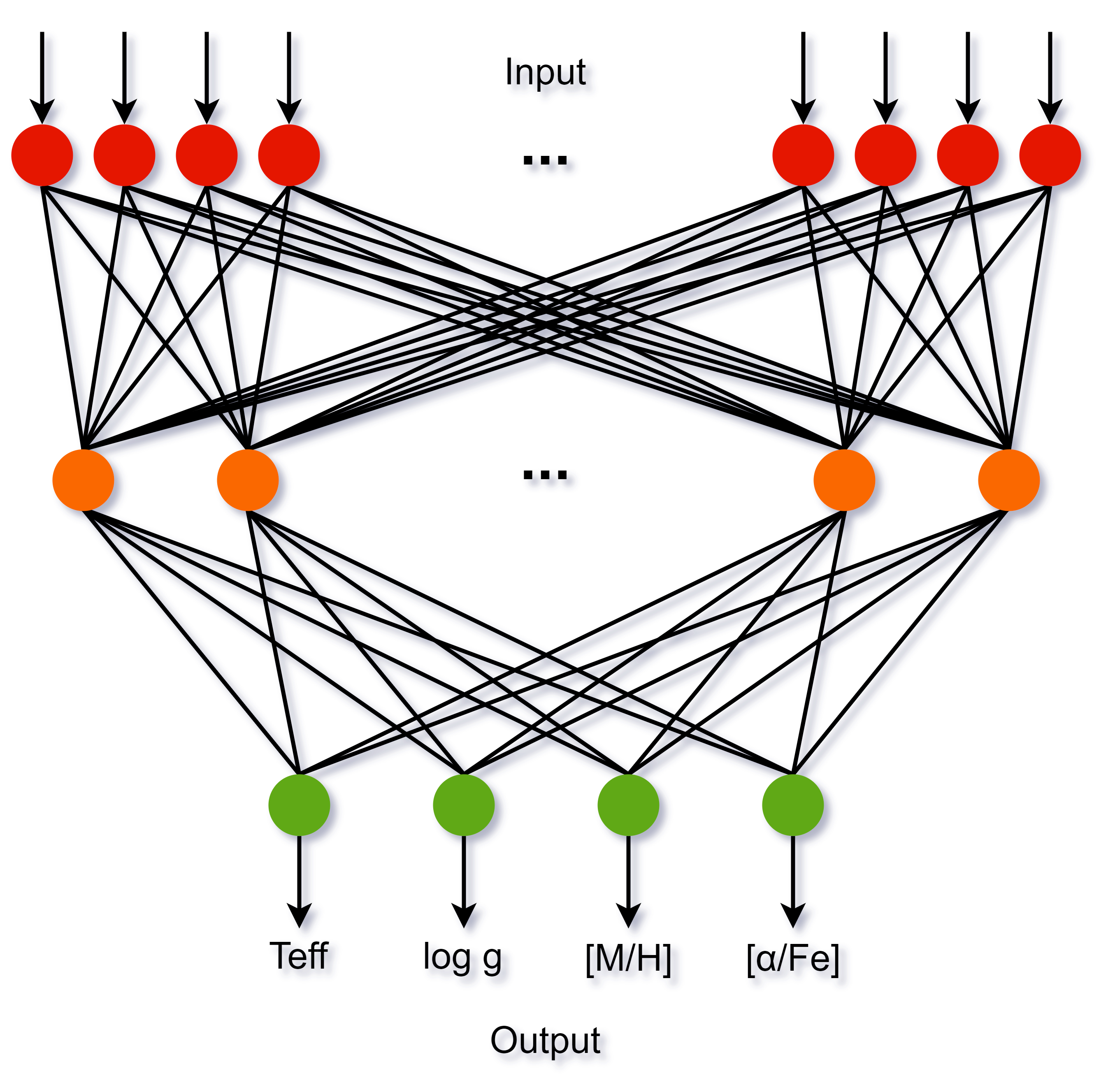
The Artificial Neural Network (ANN) parameterisation procedure is responsible for the GSP-Spec atmospheric parameters published on the astrophysical_parameters_supp table. The architecture used for ANN is feed-forward with three fully connected layers, see Figure 11.22. The input layer has as many neurons as predictor variables and the output layer has as many neurons as variables to be predicted. In this case, the input layer corresponds to the pixels in the spectrum (800) and the output layer to the four APs. The hidden layer connect both input and output layers and the number of neurons has been determined empirically between 50 and 100 for nets trained with low to high SNR spectra, respectively. The ANN analysis procedure is as follows:
1.
ANN selection: ANN behaves well in the presence of noise (Manteiga et al.2010), proving that it is a robust method when performing the estimation of APs. However, the error in the estimates depends on the signal to noise ratio (SNR) so, in order to reduce the error in the estimation, we decided to discriminate between five SNR ranges, see Table 11.21, training a network for each range.
For each spectrum we use the SNR value, given by CU6, to select which net performs the parameter estimation.
2.
Check boundaries: Some RVS spectra have NaN values at the beginning or at the end of the spectrum, caused by radial velocity corrections, that could lead to a heavy variation in flux. This can be interpreted as an important characteristic by the ANN, and to avoid this behaviour, we truncate these zero values to the mean of the spectrum.
3.
Normalisation: A min-max normalisation procedure is applied to the RVS spectra (800 pixels) to avoid geometric biases, and to ensure that all dimensions of the spectrum are in the same range to have the same importance in training.
4.
Parameter estimation: Once the net has been selected, it is fed with the normalised spectrum deriving the estimations of , , and [/Fe]. These parameters are also normalised so, a de-normalisation procedure is applied to return the correct values.
5.
Monte Carlo iterations using flux uncertainties: The same procedure used for MatisseGauguin (see item 9 above) is also applied for ANN, obtaining the median, upper and lower confidence values from quantiles 50th, 84th and 16th, respectively.
Figure 11.22: ANN architecture for atmospheric parameter determination from RVS spectra.
The activation function used for input and output layers is lineal, but for the hidden layer the logistic function is the chosen one.
The learning function used to train ANNs is the back-propagation algorithm, that can be interpreted as a problem of minimization of the error existing between the obtained and desired outputs.
In order to select the ANN that best generalizes avoiding the overtraining, we use the early stopping procedure, obtaining the net that minimize the error by stopping the training at the point when performance starts to degrade. We also initialize weights in the range [-0.2,0.2].
The learning rate, used to determine the speed and quality of learning, has been determined empirically in the range [0.001, 0.2].
Due to the fact that the effectiveness of the ANN depends on the input ordering, we perform ten trains with different initializations, selecting the one with minimum error. Each train has a limit of one thousand iterations because we observed that beyond that number, the training process does not improve but the computational cost increases.
To train ANNs we use the grid of synthetic spectra mentioned before (Section 11.3.4), since there is no noise model of Gaia RVS, we empirically determined the relation between the noise given by CU6 and the Gaussian noise that we have to use to train the nets, as it is shown in Table 11.21
Table 11.21: SNR equivalences between ANN networks and RVS spectra.
ANN
25
30
35
40
50
RVS
[20, 24]
[24, 40]
[40, 68]
[68, 108]
[108, ]
To guarantee that all inputs are in a comparable range, all spectra used to train ANNs must be normalized with the same procedure. Desired parameters (, , and [/Fe]) are also normalized in order to have the same importance in the training process. In this case, the normalization is performed using the maximum and minimum values of the grid.
As a result, we obtained five trained nets to estimate the atmospheric parameters according to these SNR ranges. Each network estimates the parameters of a given spectrum according to the signal to noise ratio provided by CU6.
Output
MatisseGauguin results provide 23 independent APs in the astrophysical_parameters table. This includes: , log g, , [/Fe], goodness-of-fit over the entire spectral range, individual chemical abundances of [N/Fe], [Mg/Fe], [Si/Fe], [S/Fe], [Ca/Fe], [Ti/Fe], [Cr/Fe], [Fe/M], [FeII/M], [Ni/Fe], [Zr/Fe], [Ce/Fe], [Nd/Fe], CN equivalent width and its fitting parameters, DIB equivalent width and its fitting parameters. In addition, for each atmospheric parameter, chemical abundance and equivalent width, upper and lower confidence values are provided. For each chemical element abundance, the number of used spectral lines, as well as the line-to-line scatter are presented.
ANN results provide 4 APs in the astrophysical_parameters_supp table. This includes: , , , [/Fe] and their upper and lower confidence values and a goodness-of-fit over the entire spectral range.
Finally, following the results of the internal GSPspec validation, a GSPspec catalogue flag has been implemented during the post-processing and published in both the astrophysical_parameters and the astrophysical_parameters_supp tables. The GSPspec catalogue flag is a chain of 41 characters including all the adopted failure criteria and uncertainty sources considered during the post-processing. In this chain, value “0” is the best, and “9” is the worse, generally implying the parameter masking.
The order of the individual flags is listed in Table 11.22, including the possible adopted values for each of them. Please refer to Recio-Blanco et al. (2023) for a detailed description of the GSPspec catalogue flags.
Table 11.22: Definition of each character in the GSP-Spec quality flag chain for MatisseGauguin, including the possible values. Flag names are split in three categories: parameter flags (green), individual abundance flags (blue), DIB flag (red) and DeltaCnq flag (magenta). All flags apply to MatisseGauguin algorithm, while to ANN algorithm only the parameter flags are applied except KMgiantPar.
Chain character
Considered
Possible
number - name
quality aspect
adopted values
1 vbroadT
vbroad induced bias in
0,1,2,9
2 vbroadG
vbroad induced bias in
0,1,2,9
3 vbroadM
vbroad induced bias in
0,1,2,9
4 vradT
vrad induced bias in
0,1,2,9
5 vradG
vrad induced bias in
0,1,2,9
6 vradM
vrad induced bias in
0,1,2,9
7 fluxNoise
flux noise uncertainties
0,1,2,3,4,5,9
8 extrapol
extrapolation
0,1,2,3,4,9
9 negFlux
negative flux pixels
0,9
10 nanFlux
NaN flux pixels
0,1,9
11 emission
emission line
0,1,9
12 nullFluxErr
null uncertainties
0,1,9
13 KMgiantPar
KM-type giant stars
0,1,2,9
14 NUpLim
Nitrogen abundance upper limit
0,1,2,9
15 NUncer
Nitrogen abundance uncertainty quality
0,1,2,9
16 MgUpLim
Magnesium abundance upper limit
0,1,2,9
17 MgUncer
Magnesium abundance uncertainty quality
0,1,2,9
18 SiUpLim
Silicon abundance upper limit
0,1,2,9
19 SiUncer
Silicon abundance uncertainty quality
0,1,2,9
20 SUpLim
Sulphur abundance upper limit
0,1,2,9
21 SUncer
Sulphur abundance uncertainty quality
0,1,2,9
22 CaUpLim
Calcium abundance upper limit
0,1,2,9
23 CaUncer
Calcium abundance uncertainty quality
0,1,2,9
24 TiUpLim
Titanium abundance upper limit
0,1,2,9
25 TiUncer
Titanium abundance uncertainty quality
0,1,2,9
26 CrUpLim
Chromium abundance upper limit
0,1,2,9
27 CrUncer
Chromium abundance uncertainty quality
0,1,2,9
28 FeUpLim
Neutral iron abundance upper limit
0,1,2,9
29 FeUncer
Neutral iron abundance uncertainty quality
0,1,2,9
30 FeIIUpLim
Ionised iron abundance upper limit
0,1,2,9
31 FeIIUncer
Ionised iron abundance uncertainty quality
0,1,2,9
32 NiUpLim
Nickel abundance upper limit
0,1,2,9
33 NiUncer
Nickel abundance uncertainty quality
0,1,2,9
34 ZrUpLim
Zirconium abundance upper limit
0,1,2,9
35 ZrUncer
Zirconium abundance uncertainty quality
0,1,2,9
36 CeUpLim
Cerium abundance upper limit
0,1,2,9
37 CeUncer
Cerium abundance uncertainty quality
0,1,2,9
38 NdUpLim
Neodymium abundance upper limit
0,1,2,9
39 NdUncer
Neodymium abundance uncertainty quality
0,1,2,9
40 DeltaCNq
Cyanogen differential equivalent width quality
0,1,2,9
41 DIBq
DIB quality flag
0,1,2,3,4,5,9
Scope
All results are provided for stars with SNR20 (for an estimate of the RVS signal-to-noise see the expectedsigtonoise field). During the post-processing, dubious results were filtered out based on processing flags. In particular, results out of the validity range of the reference synthetic spectra grids (essentially FGK-type stars) are flagged thanks to the extrapolation character of the GSP-Spec catalogue flag chain.
Results
A detailed description of GSP-Spec results, including an in depth analysis of methodological biases and comparison with literature parameters can be found in Recio-Blanco et al. (2023). Gaia self-consistent calibrations are proposed for the observed biases. It is important to underline the fact that the use of GSP-Spec catalogue flags is crucial for any scientific use of the GSP-Spec results.
Notes on ANN observed biases
ANN shows no important internal bias as inferred from tests with synthetic spectra, see Table 11.23. However, compared to the literature, ANN results present important biases that have to be taken into account, see Table 11.24.
Table 11.23: ANN training errors with a randomly selected dataset of approximately 10000 synthetic spectra.
SNR 50
MAD
19.48 K
173.90 K
102.36 K
0.02 dex
0.24 dex
0.16 dex
0.03 dex
0.19 dex
0.13 dex
0.01 dex
0.10 dex
0.06 dex
SNR 40
MAD
30.34 K
246.06 K
149.01 K
0.07 dex
0.38 dex
0.25 dex
0.01 dex
0.27 dex
0.18 dex
0.02 dex
0.13 dex
0.09 dex
SNR 35
MAD
38.73 K
291.44 K
179.13 K
0.01 dex
0.46 dex
0.31 dex
0.07 dex
0.31 dex
0.21 dex
0.02 dex
0.15 dex
0.11 dex
SNR 30
MAD
21.94 K
357.57 K
233.12 K
0.01 dex
0.57 dex
0.41 dex
0.05 dex
0.39 dex
0.28 dex
0.01 dex
0.18 dex
0.13 dex
SNR 25
MAD
1.55 K
460.13 K
318.13 K
0.01 dex
0.74 dex
0.56 dex
0.03 dex
0.51 dex
0.38 dex
0.01 dex
0.21 dex
0.16 dex
Table 11.24: ANN biases and mean absolute deviations comparing with literature values.
SNR 50
Bias
MAD
-106.97 K
146.27 K
-0.13 dex
0.21 dex
-0.26 dex
0.14 dex
0.07 dex
0.05 dex
SNR 40
Bias
MAD
-103.58 K
151.37 K
-0.21 dex
0.33 dex
-0.26 dex
0.14 dex
0.11 dex
0.07 dex
SNR 35
Bias
MAD
-117.76 K
160.61 K
-0.19 dex
0.34 dex
-0.27 dex
0.17 dex
0.14 dex
0.08 dex
SNR 30
Bias
MAD
-173.92 K
204.83 K
-0.33 dex
0.46 dex
-0.41 dex
0.21 dex
0.17 dex
0.11 dex
SNR 25
Bias
MAD
-413.42 K
253.29 K
-0.61 dex
0.48 dex
-0.50 dex
0.27 dex
0.15 dex
0.12 dex
In Figure 11.23 the parameterisation for all stars (5 524 387) is shown, considering all possible flag values.
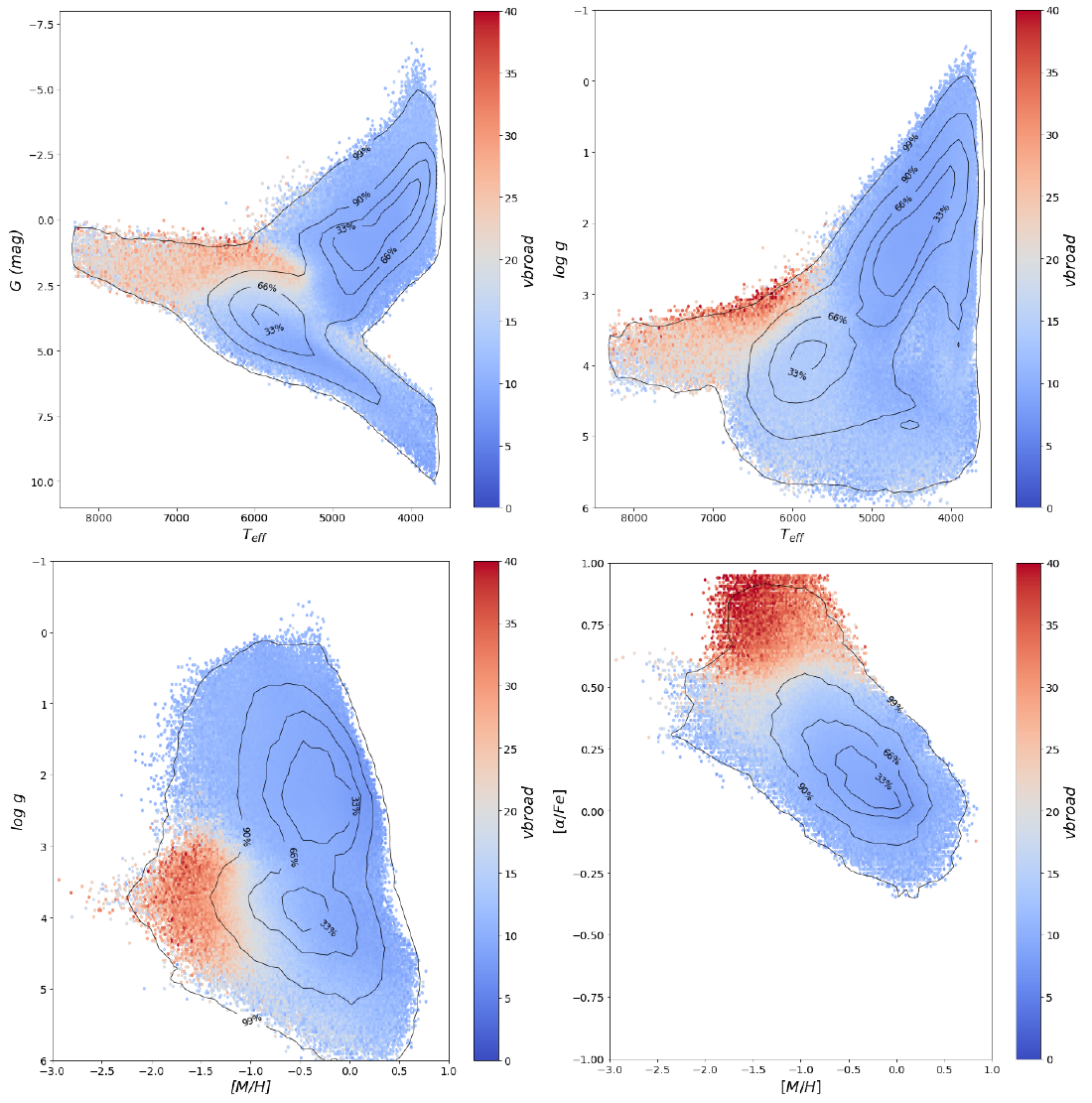
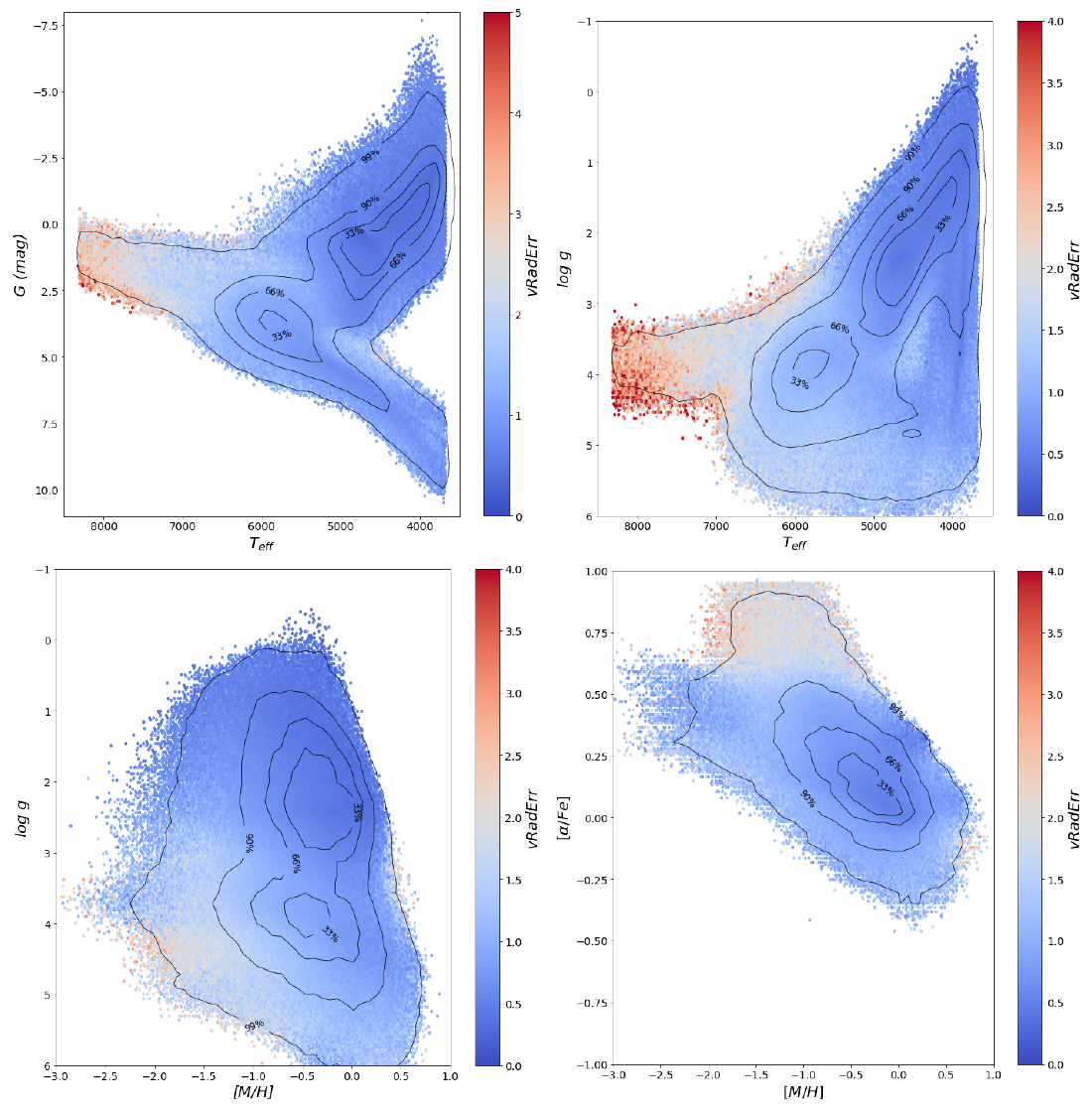
Plots in Figure 11.24 and Figure 11.25 show that the stars with vbroad values greater than 20 km/s, or radial velocity errors greater than 2 km/s, occupy specific regions of the parameter space, mostly coincident for both.
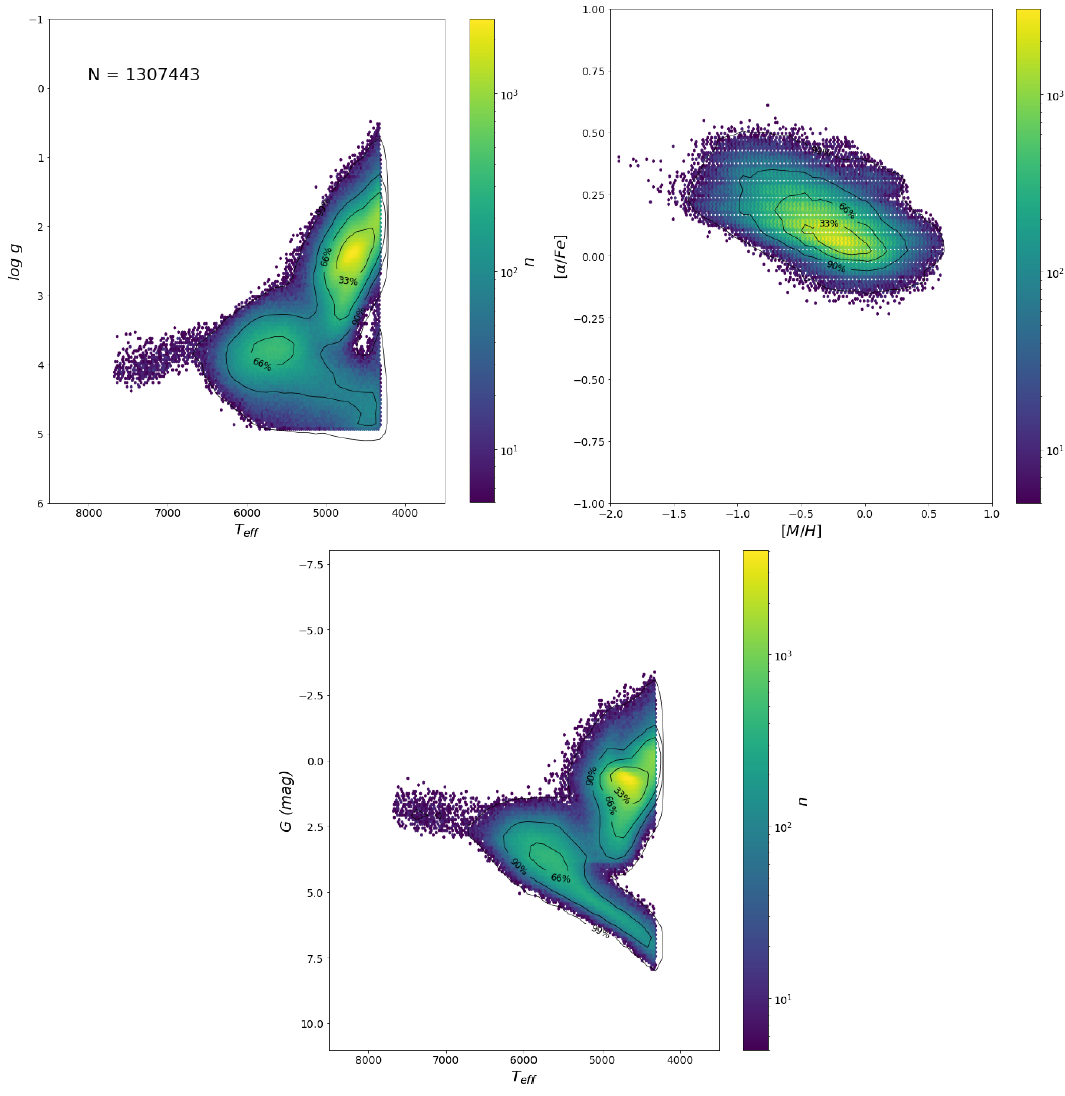
In Figure 11.26 only the best quality parameterisations are shown (1 307 443), this means stars with no bias induced by vbroad nor radial velocity, also stars with noise uncertainties flag equals to 0 and parameters without extrapolations.
Figure 11.23: - (top left), - (top right) and - diagrams for all of the stars. The colour code is . Contour lines comprise 33, 66, 90, and 99 per cent of the stars. Plotted the median values with a minimum density of 5 stars.
Figure 11.24: Vbroad effect on GSP-Spec-ANN results in the astrophysical_parameters_supp table. - diagram (top left), the Kiel diagram (top right), the - diagram (bot left) and finally the - diagram. The colour-code is the vbroad of the stars, and saturates at 40 km/s. Contour lines comprise 33, 66, 90, and 99 per cent of the stars. Plotted the median values with a minimum density of 5 stars.
Figure 11.25: - diagram (top left), the Kiel diagram (top right), the - diagram (bot left) and finally the - diagram. The colour-code is the radial velocity error of the stars, and saturates at 4 km/s. Contour lines comprise 33, 66, 90, and 99 per cent of the stars. Plotted the median values with a minimum density of 5 stars.
Figure 11.26: - (top left), - (top right) and - diagrams for best quality stars. The colour code is . Contour lines comprise 33, 66, 90, and 99 per cent of the stars. Plotted the median values with a minimum density of 5 stars.