10.5.2 Three-dimensional clustering test
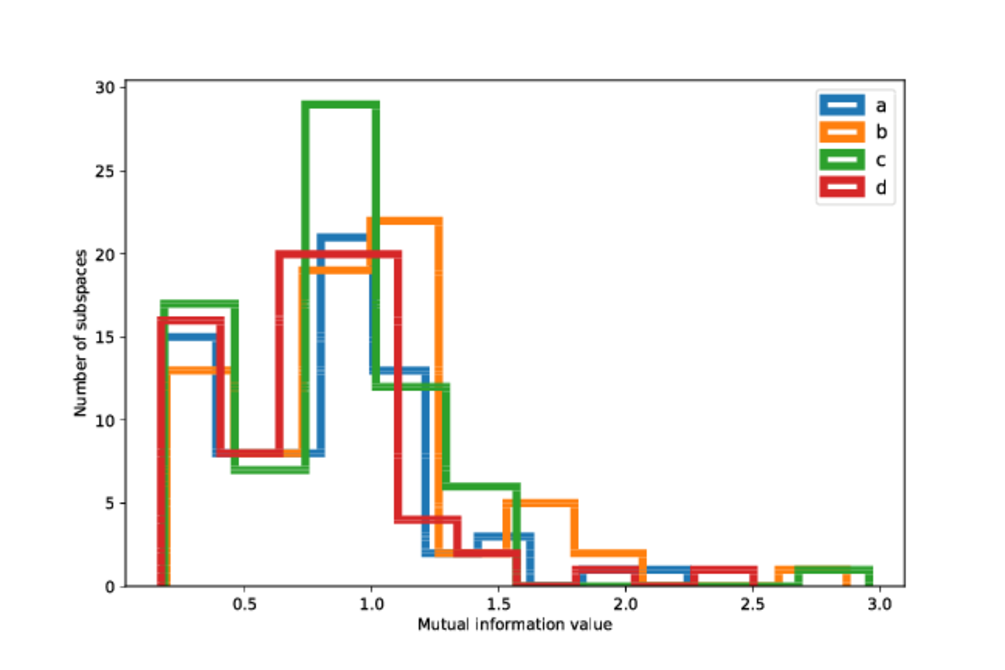
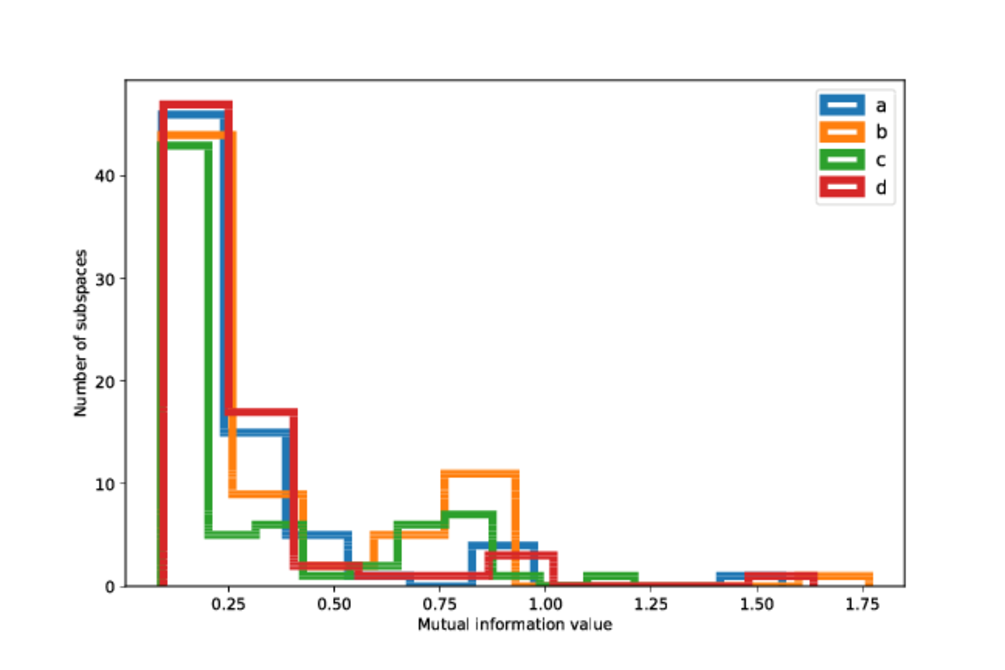
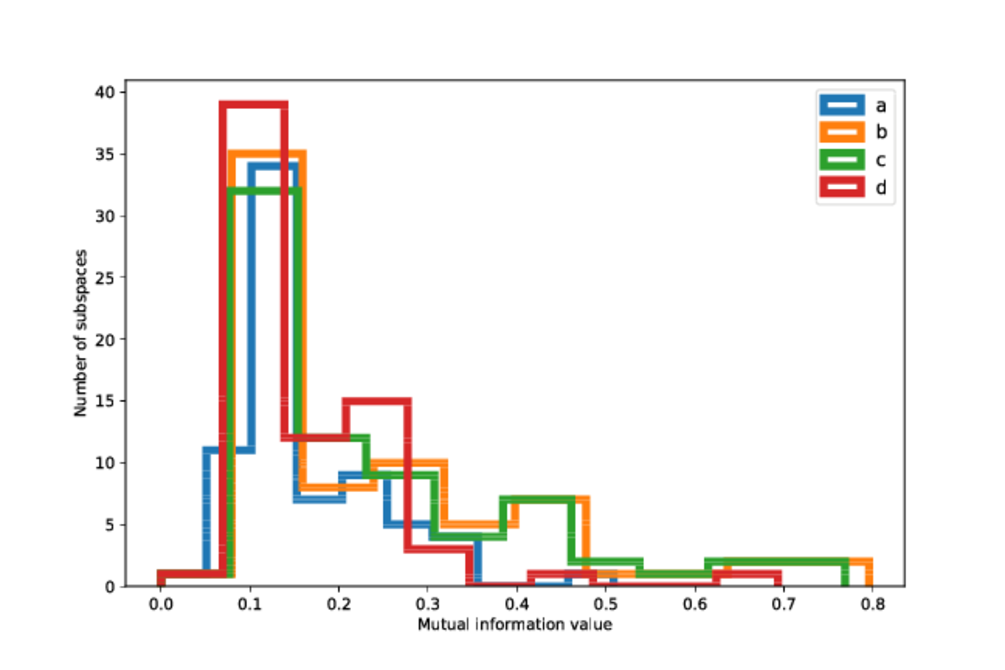
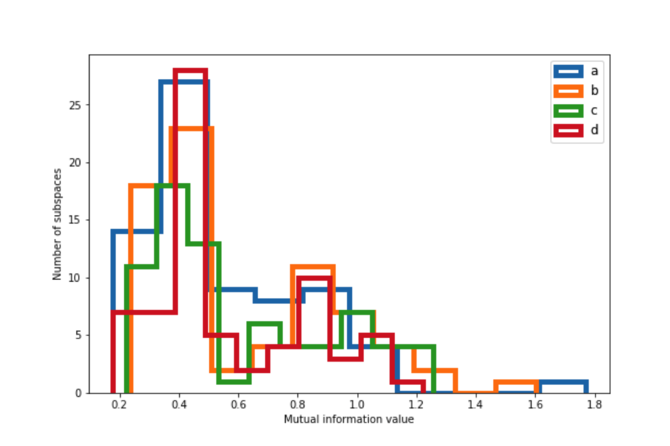
We quantify the degree of clustering in the four regions on the sky in 3D, where we consider the subspaces spanned by ra, dec and another astrometric or photometric observable or uncertainty. The purpose of this is to test whether an observable shows a different degree of clustering based on the sky position and number of observations. This test shows that the degree of clustering is the same between the different patches of the sky, and this result is consistent also for the filters listed in Table 10.5, especially for the pairs of regions that have similar numbers of observations.
Comparing the degree of clustering in the data between the different filters we see that the data appears to be more clustered for the brighter stars (the KLD values are on average larger for the BT11 subset). This is shown on Figure 10.34 where we show the KLD distributions for the filters BT11 (), BT17 (), FT20 () and for the unfiltered data. The reason that the BT11 is more clustered than the other samples is because it is made of mainly nearby stars, and for these stars the values of their observables and associated uncertainties span small ranges. On the other hand, the BT17 and other subsets that contain stars that are both nearby and at intermediate and large distances, making the values of their observables and uncertainties to span much larger ranges.
We also see that the DUPLICATES subset shows larger clustering than the unfiltered or subsets like (DUPVISA, DUPMATA), as expected. The filters DUPVISA and DUPMATA show the smallest degree of clustering amongst all filters, including the unfiltered data.